Database Partitioning: A Guide to Scaling and Performance Optimization
Horizontal and Vertical Partitioning Strategies for Modern Applications

As systems grow, managing databases effectively becomes crucial to ensuring scalability and high availability. One of the most common techniques used to handle increasing data loads is database partitioning. Partitioning refers to the process of dividing a large database into smaller, more manageable pieces, or partitions. Each partition can then be stored and processed independently, often improving performance, availability, and scalability.
What is Database Partitioning?
Database partitioning is the act of breaking down a large table into smaller, more manageable chunks. Partitioning can be done horizontally or vertically, depending on the use case.
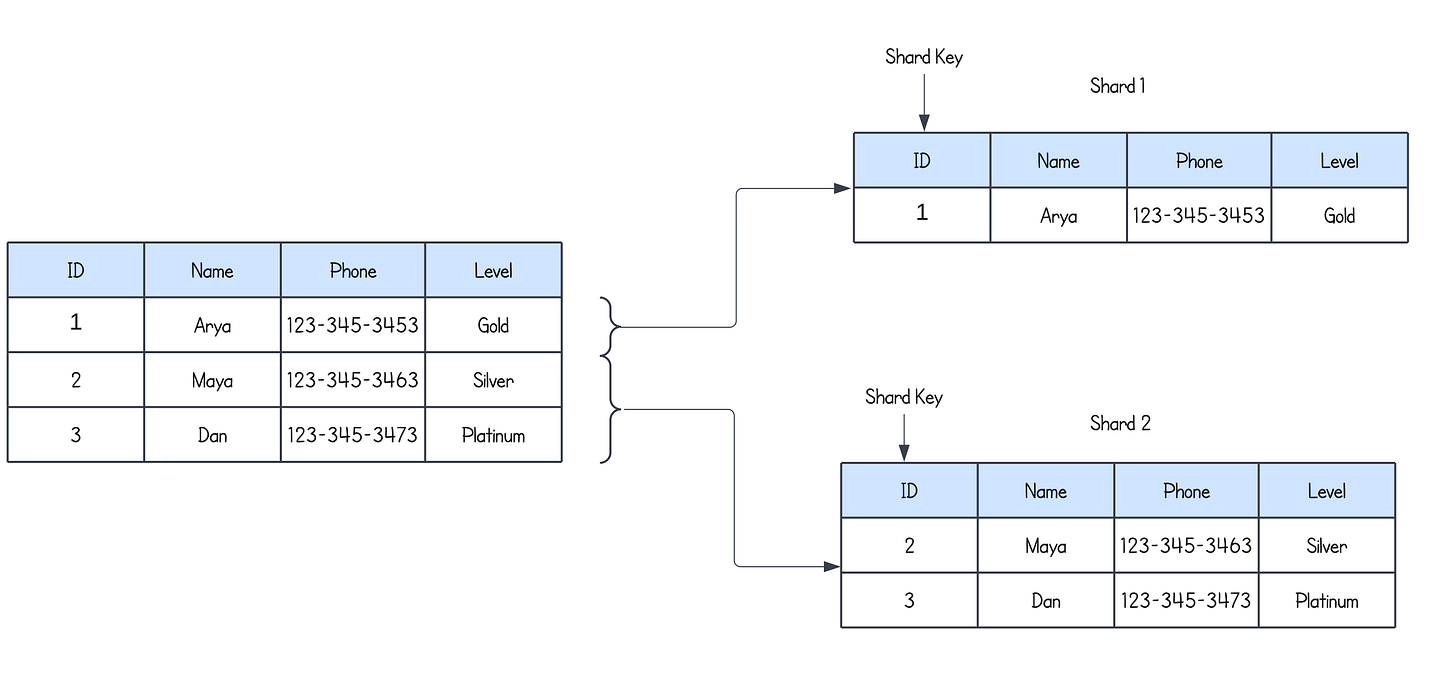
Horizontal Partitioning (Sharding): This involves splitting a table's rows into separate partitions. Each partition may be stored on a different database server or node, which helps distribute the load. For example, you might split a user table by the first letter of the user's last name or by a range of user IDs.
Example:Imagine a user database with millions of users. To distribute the load:
Partition 1: Users with IDs 1 on Server A.
Partition 2: Users with IDs 2 to 3 on Server B.
This approach ensures that queries for users are distributed and not bottlenecked by a single server.
Benefits of Horizontal Partitioning:
Scalability: Adding more nodes distributes the load further.
Improved Query Performance: Smaller datasets mean faster queries.
Availability: If one partition (node) fails, others remain unaffected.
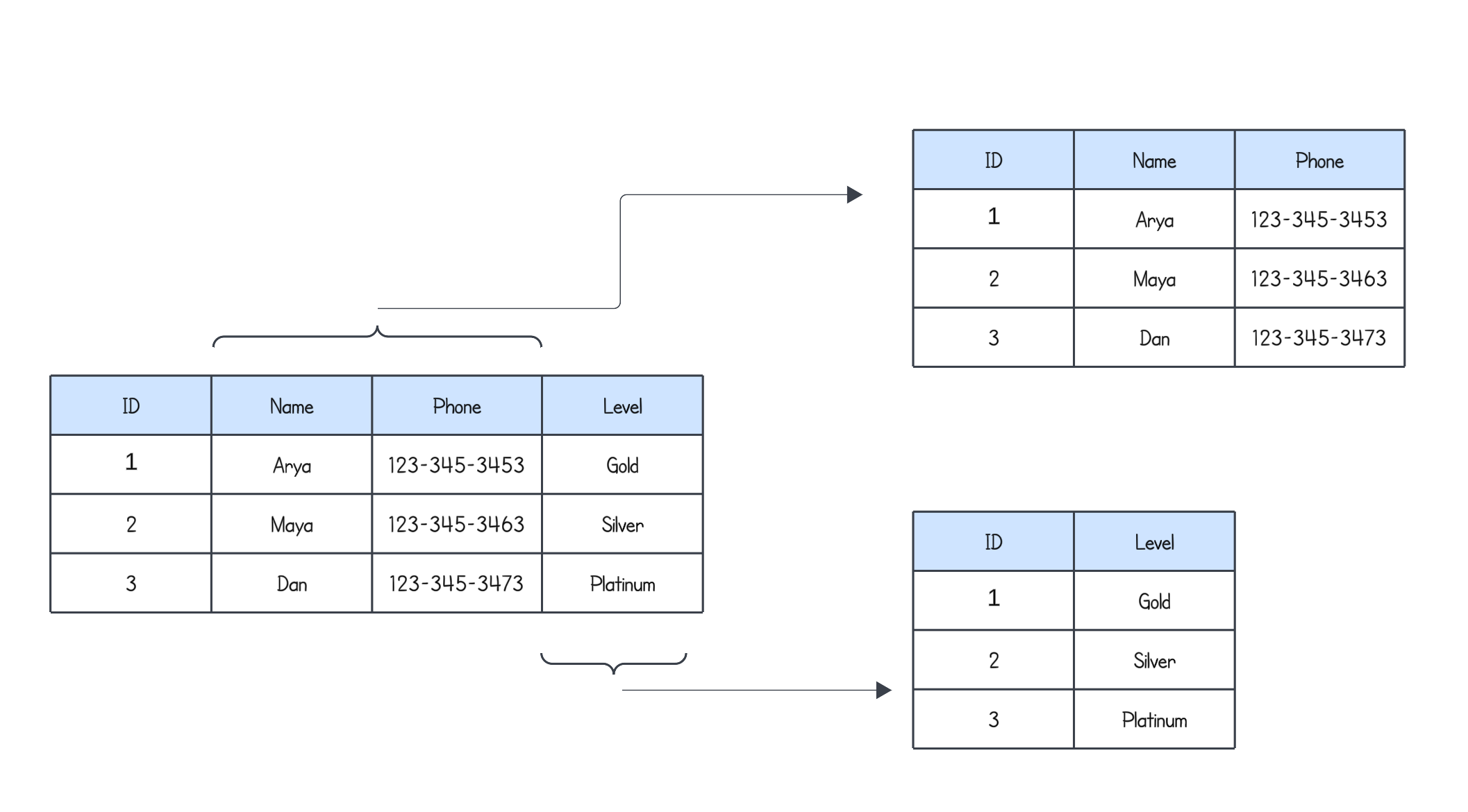
Vertical Partitioning: This involves dividing a table's columns into different partitions. For instance, one partition might store a subset of columns (like user personal details), and another partition stores other details (like preferences). This is less common than horizontal partitioning but can be useful for handling large tables with varying data access patterns.
Example:For a user profile table:
Partition 1: Basic info like
user_id,name, andphone.Partition 2: Optional data like
userId, andlevel.Queries that only need basic user info don’t have to read large, infrequently accessed data.
Benefits of Vertical Partitioning:
Efficient Access Patterns: Queries only read necessary columns.
Optimized Storage: Different partitions can use different storage solutions (e.g., faster storage for frequently accessed data).
Why Partitioning Matters
Performance: Smaller partitions mean faster queries and updates.
Scalability: Easily add more servers to distribute partitions.
Maintenance: Simplifies backups, migrations, and schema changes.
Availability: Isolate failures to specific partitions.
Best Practices for Database Partitioning
Choose the Right Partition Key: For horizontal partitioning, select a key that evenly distributes the data (e.g., user ID).
Monitor Growth: Ensure partitions don't become too large over time.
Use Tools for Coordination: Distributed systems often use tools like Zookeeper or etcd to manage partition metadata and routing.